Warum Architekturregeln wichtiger werden, wenn KI den Code schreibt
KI schreibt heute in Sekunden Code, der kompiliert und dessen Tests grün werden. Was sie nicht mitliefert, ist Architektur. Genau deshalb wird eine zwanzig Jahre alte Idee wieder hochaktuell: die Hexagonale Architektur, abgesichert durch automatische Tests.
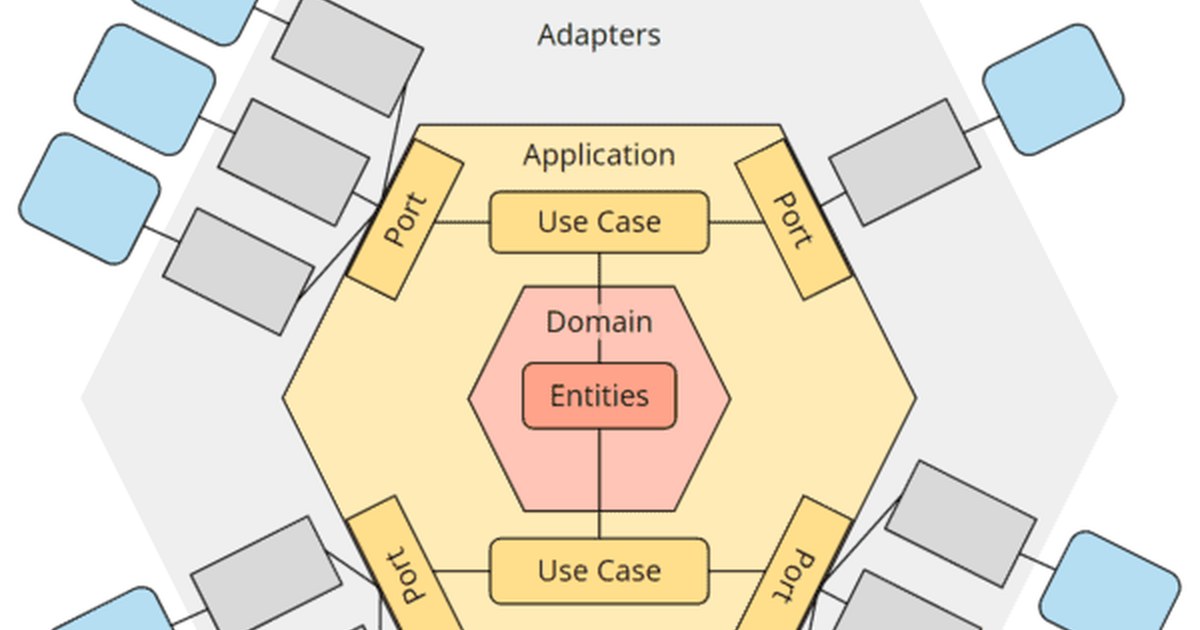
Die Grundidee: Das Hexagon
Die Hexagonale Architektur, auch bekannt als Ports & Adapters Pattern, wurde 2005 von Alistair Cockburn beschrieben. Ihre Kernidee ist radikal einfach:
Die Fachlogik kennt die Außenwelt nicht. Die Außenwelt kennt die Fachlogik nur über definierte Schnittstellen.
Der Name ist Absicht. Ein Sechseck hat viele gleichwertige Seiten, und jede ist ein möglicher Ein- oder Ausgang. Die Anwendung sitzt in der Mitte, alles andere ist austauschbar. Datenbank, REST-API, Messagebroker, UI: nichts davon gehört zum Kern. Es sind Gäste, die anklopfen müssen, bevor sie eintreten.
Die Schichten, und was in jede gehört
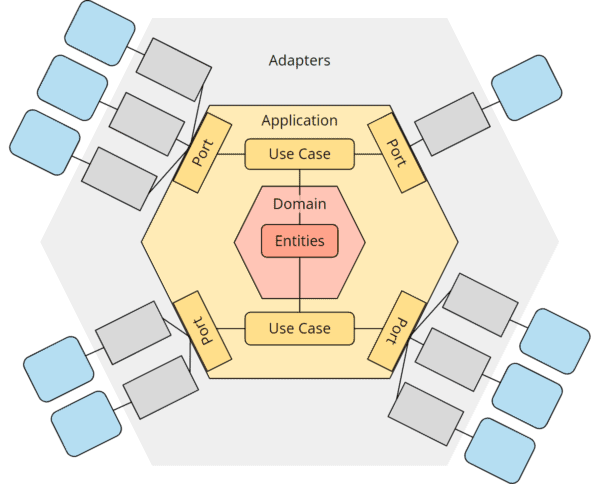
Domain: das unveränderliche Herz
Die Domain enthält ausschließlich Fachlogik. Hier leben die Begriffe, die auch ein Nicht-Techniker versteht: ein Kanban-Board, ein Item, eine Spalte, die Regel, dass ein archiviertes Item nicht mehr verschoben werden darf.
Was die Domain nicht kennt: Datenbanken, HTTP, Frameworks, JSON. Keine technischen Abhängigkeiten, keine externen Konzepte. Würde man sie herauslösen und in ein leeres Projekt legen, liefe sie ohne eine einzige Änderung weiter.
Das ist kein Zufall, sondern eine bewusste Entscheidung mit konkreter Konsequenz: Die Fachlogik lässt sich ohne laufende Datenbank, ohne Framework-Kontext und ohne Netzwerk testen. Das macht Tests schnell und den Code verständlich.
Application: der Dirigent
Die Application-Schicht orchestriert. Sie weiß, in welcher Reihenfolge die Fachlogik aufgerufen wird, welche Daten geladen und was danach gespeichert werden muss. Fachliche Entscheidungen trifft sie nicht selbst, die überlässt sie der Domain.
Mit der Außenwelt spricht sie ausschließlich über Ports: klar definierte Schnittstellen, die beschreiben, was gebraucht wird, ohne festzulegen, wie es geliefert wird.
Use Case: der Vertrag nach innen
Ein Use Case beschreibt, was die Anwendung kann, aus Sicht dessen, der sie aufruft. „Verschiebe dieses Item“, „Archiviere diesen Eintrag“, „Erstelle ein neues Board“. Jeder Use Case ist eine einzelne, klar benannte Fähigkeit.
Der Aufrufer kennt nur diesen Vertrag. Er weiß nicht, wer dahintersteckt, und nicht, ob überhaupt eine Datenbank beteiligt ist. Er ruft einfach an.
Port: der Vertrag nach außen
Ausgehende Ports funktionieren umgekehrt. Die Application definiert, was sie von der Außenwelt braucht: „Gib mir dieses Board“, „Speichere diesen Zustand“. Wie das geliefert wird, entscheidet die Infrastruktur.
Entscheidend: Diese Verträge gehören zur Application, nicht zur Infrastruktur. Die Abhängigkeit zeigt immer nach innen, niemals nach außen.
Adapter: die Brücke zur Welt
Adapter sind die Übersetzer an der Grenze zwischen technischer Außenwelt und fachlichem Kern.
Primäre Adapter treiben die Anwendung an. Ein REST-Controller nimmt einen HTTP-Request entgegen, übersetzt ihn in einen Use-Case-Aufruf und gibt das Ergebnis zurück. Was hinter dem Use Case steckt, weiß er nicht.
Sekundäre Adapter werden von der Anwendung angetrieben. Ein Persistence-Adapter nimmt ein Domain-Objekt entgegen, übersetzt es in eine Datenbankzeile und speichert sie. Die Domain weiß davon nichts.
Infrastructure: die technische Basis
Hier lebt alles Technische: Datenbankentitäten, Framework-Konfiguration, Sicherheitseinstellungen, Migrationsskripte. Die Infrastruktur kennt alle anderen Schichten. Keine andere Schicht kennt die Infrastruktur direkt.
Die eine Regel, die alles zusammenhält
Alle Schichten folgen einer einzigen Grundregel:
Abhängigkeiten zeigen immer nach innen.
Die Domain kennt niemanden. Die Application kennt nur die Domain. Die Adapter kennen die Application. Die Infrastruktur kennt alle. Nie umgekehrt.
Die Regel klingt einfach, und sie ist es auch, solange man sie einhält. Das Problem ist der Zeitdruck. Ein direkter Import hier, eine schnelle Abkürzung dort. Jeder einzelne Verstoß wirkt harmlos. In der Summe entsteht der „Big Ball of Mud“: eine Codebasis, in der alles mit allem zusammenhängt und niemand mehr etwas ändern kann, ohne an drei anderen Stellen etwas zu brechen.
ArchUnit: die Architektur als automatischer Test
Hier kommt ArchUnit ins Spiel. Die Java-Bibliothek macht Architekturregeln als gewöhnliche Tests formulierbar. Sie analysiert den kompilierten Code und prüft, ob die Regeln eingehalten werden.
Die Regeln lesen sich fast wie natürliche Sprache:
- Keine Klasse in der Domain darf von der Infrastruktur abhängen.
- Alle Use Cases und Ports müssen Interfaces sein, keine Klassen.
- JPA-Datenbankentitäten dürfen nur in der Infrastruktur existieren.
- Controller dürfen nur über Ports sprechen, nie direkt mit dem dahinterliegenden Service.
- Die Domain trägt keine Framework-Annotationen.
Der entscheidende Unterschied zu einem Architektur-Dokument im Wiki: ArchUnit scheitert den Build, sobald eine Regel verletzt wird. Kein Merge ohne grüne Tests, und die Architektur ist einer dieser Tests.
Wird eine Regel verletzt, nennt ArchUnit exakt die Klasse, die Methode und die Zeile, die dagegen verstößt. Keine vage Warnung, kein stiller Fehler, sondern eine klare und umsetzbare Meldung.
Warum das mit KI-Code noch wichtiger wird
Ein Sprachmodell optimiert auf lokale Korrektheit. Der Code löst das unmittelbare Problem, er kompiliert, die Tests werden grün. Einen inhärenten Anreiz, globale Architekturregeln einzuhalten, hat das Modell nicht, es sei denn, man weist es explizit darauf hin oder der Build schlägt fehl.
In der Praxis heißt das: Ohne Leitplanken nimmt KI-generierter Code den direkten Weg. Eine Datenbankabhängigkeit direkt im fachlichen Kern. Eine technische Annotation direkt im Domain-Objekt. Jede einzelne Entscheidung ist lokal nachvollziehbar, in der Summe erodiert die Architektur.
ArchUnit ist eine dieser Leitplanken, und es argumentiert nicht, es scheitert. Der Build bleibt rot, bis die Regel eingehalten wird, egal ob der Code von einem Menschen oder einer KI stammt.
Das verändert die Zusammenarbeit mit KI-Tools grundlegend. Statt nach jedem generierten Abschnitt von Hand zu prüfen, ob die Architektur noch stimmt, übernimmt ArchUnit das automatisch und zuverlässig. Die KI darf schnell sein. Der Build sorgt dafür, dass schnell nicht zulasten von richtig geht.
Was sich in der Praxis ändert
Ein Datenbankwechsel bedeutet: einen neuen Adapter schreiben, den alten entfernen. Fachlogik und Orchestrierung bleiben unberührt, denn sie haben nie gewusst, welche Datenbank dahintersteckt.
Fachlogik verstehen bedeutet: ins Herz der Anwendung schauen, ohne sich durch technische Konzepte zu kämpfen. Die Geschäftsregeln stehen genau dort, wo ihr Name es verspricht.
Testen bedeutet: Die Fachlogik läuft im Test ohne Datenbankverbindung und ohne Framework-Kontext. Schnell, isoliert, zuverlässig. Integrationstests beschränken sich auf die Adapter, die sie wirklich brauchen.
Architektur-Drift wird sofort sichtbar. Nicht nach sechs Monaten beim nächsten großen Refactoring, sondern im nächsten Build-Lauf.
Fazit
Hexagonale Architektur beantwortet eine alte Frage: Wie schreibt man Software, die in drei Jahren noch wartbar ist? Indem man die Fachlogik von der Technik trennt, die Grenzen klar benennt und dann automatisch sicherstellt, dass diese Grenzen nicht stillschweigend verschwinden.
ArchUnit macht aus dem letzten Punkt einen Test. In jedem Projekt ist das wertvoll. In einem Projekt mit KI-Assistenten ist es unverzichtbar.
Gute Leitplanken machen nicht langsamer. Sie sind die Voraussetzung dafür, schnell zu sein, ohne fahrlässig zu werden.
Schreibe einen Kommentar